
개요
- Apache Hadoop; Hadoop
- 아파치 하둡; 하둡, 허둡 /həˈduːp/
- 빅 데이터 처리 프레임워크
- 대용량 데이터 처리 분석을 위한 분산 컴퓨팅 지원 프레임워크
- 분산파일시스템 + 분산처리시스템
- 분산 저장 + 분산 처리
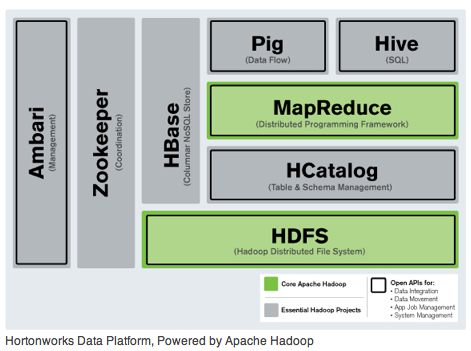
- HDFS + 맵리듀스[1]
- 여러 개의 컴퓨터를 하나로 묶어 저장 공간과 계산 능력 향상
- 하드웨어 비용 절감 가능[2]
- 오픈 소스
- 보통 리눅스 기반[3]
![]()
장점
- 부하 분산
- 대용량 파일 저장 가능(HDFS)
- 장비 추가시 성능이 선형적으로 향상
- 저비용(오픈소스, 리눅스 활용)
다른 소프트웨어 연동
이 부분에 대해 더 많은 내용을 읽으려면 하둡 연동 사례 문서를 참조해 주세요.
하둡이 설치된 서버에 하둡과 연동되는 다른 소프트웨어들을 함께 설치하여 사용하는 경우가 많다.
- 연동사례
같이 보기
참고
- 위키백과 "아파치 하둡"
- 영어 위키백과 "Apache_Hadoop"
- http://navercast.naver.com/contents.nhn?rid=122&contents_id=44732
- ↑ 최초 접근시에는 2가지를 분리하여 생각할 필요가 있음. HDFS는 상당히 안정적인 일종의 스토리지.
- ↑ 고성능 서버는 필요 이상으로 비싸다...
- ↑ 물론 MS에서 윈도우 기반 하둡을 제공한다. http://www.microsoft.com/en-us/sqlserver/solutions-technologies/business-intelligence/big-data.aspx